On the one hand, Image Recognition Technology is a vital component of computer vision systems — a broader field aiming to replicate human vision in machines, encompassing more than just image interpretation. On the other hand, Image Recognition Technology helps empower system tools for identifying photos that may use algorithms and models to interpret the visual world.
As a result, it helps convert images into symbolic information for use in various applications. Regarding Machine Learning (ML), Image Recognition Technology is a methodological discipline that helps train computers to interpret and understand the visual world. It involves algorithms and models designed to identify and categorize images based on patterns and objects within them.
By converting images into numerical or symbolic data, image recognition tools can make sense of the world like human vision. In short, through Image Recognition Technology, machines can identify and classify specific objects, people, text, and actions within digital images and videos. Computer software can “see” and interpret things within visual media the way a human might.
Therefore, it’s worth mentioning that the importance of image recognition technology in cloud computing is profound. Its applications, from healthcare to security, retail, and social media, are ubiquitous, revolutionizing industries by automating tasks that once required human vision and cognition. This article explores why image recognition technology is essential in identifying digital photos.
How Image Recognition Technology Helps In Cloud Computing
For beginners, it’s worth reminding you that Image Recognition Technology is a technique that helps identify places, logos, people, objects, buildings, and several other variables in digital images. It may be very easy for humans like you and me to recognize different photos, such as images of animals. We can quickly identify a cat image and differentiate it from a picture of a horse.
But it’s not so simple for a computer to process. A digital image comprises picture elements, also known as pixels, each with finite, discrete quantities of numeric representation for its intensity or grey level. So, the computer sees an image as numerical values of these pixels, and to recognize a specific image, it has to recognize the patterns and regularities in this numerical data.
Regarding cloud computing, defining digital images is essential to understand how image recognition works. A digital image is composed of picture elements or pixels. They are spatially organized into a two-dimensional grid or array. Each pixel has a numerical value corresponding to its light intensity or gray level. Eventually, computer vision will only do the brain’s share of the recognition work.
Computer vision trains computers to interpret and understand visuals. Just like in Optical Character Recognition (OCR), as an application of computer vision, image recognition software analyzes and processes the visual content of an image or video and compares it to learned data, allowing the software to automatically “see” and interpret what is present, the way a human might be able to.
Using Image Recognition Technology To Help Identify Digital Photos
Today, image recognition is based on deep learning — a subcategory of ML that uses multi-layered algorithms (neural networks), similar to the human brain— to analyze data and draw conclusions about it continually. In the case of image recognition, neural networks are fed with as many pre-labeled images as possible to “teach” them how to recognize similar images.
Technically, human visuals are much better than computing tools because of superior high-level image understanding, contextual knowledge, and massively parallel processing. However, human capabilities deteriorate drastically after an extended period of surveillance. Also, specific working environments are inaccessible or too hazardous for human beings.
Related Resource: The Vital OCR Technology Role In Text Creation Efficiency And Accuracy
Generally speaking, for such reasons, automatic recognition systems are developed for various applications. Driven by innovative advances in machine learning systems, Artificial Intelligence (AI), other related cloud computing tools, and image processing technology, computer mimicry of human vision has recently gained ground in several practical applications. And there is a good reason.
Markedly, image processing is a way to convert an image to a digital aspect and perform certain functions to get an enhanced image or extract other helpful information. It is a type of signal time when the input is an image, such as a video frame or image, and the output can be an image or features associated with that image. Various libraries are involved in the image processing events.
Including:
- Scikit-image
- OpenCV
- Mahotas
- SimplelTK
- SciPy
- Pillow
- Matplotlib
In simple terms, image processing helps process cloud-based data — audio editing and any conflict in the image — using a digital computer. It’s a way to do something, such as working on an image to get an enhanced image or cutting out some helpful information from it. It is considered signal processing where engagement is the image, and the crop can be an image or related topographies.
Currently, image processing is in the midst of rapid growth in technology. It also forms the main research area within engineering and computer science commands. Let’s consider the AWS Image Processing system as our preferred example. It includes treating images as two equal symbols while using the set methods—one of the fastest-growing technologies in various business sectors.
In other words, image processing is how an individual can enhance the quality of an image or gather alerting insights from an image and feed it to an algorithm to predict later things. Equally important, it’s worth noting that Graphic Design Software Tools and how they help process images also form the core of the engineering and computer science research industry space.
It Involves:
- The process of importing an image with an optical scanner or digital photography.
- Image analysis and management, including data compression, enhancement, and visual detection patterns (satellite imagery).
- It produces the final stage, where the result can be changed to an image or report based on image analysis.
As mentioned, image recognition is a subset of computer vision, a broader field of artificial intelligence that trains computers to see, interpret, and understand visual information from images or videos. Computer vision involves several “sub-problems” or “tasks,” as Khanna put it — including image classification or assigning a single label to an image such as “car” or “apple.”
This leads to more complicated tasks like object detection. It involves identifying the many things within an image (cars, animals, trees) and localizing them within the scene. Then there’s scene segmentation, where a machine classifies every image or video pixel and identifies what object is there, allowing for easier identification of amorphous objects (bushes, the sky, walls).
Real-World Image Recognition Technology Applications Usage Examples
At its core, image recognition is a process that involves a series of steps. First, an image is acquired, usually as a digital photo or video frame. Next, pre-processing is performed to enhance the image and eliminate unnecessary noise. This can include adjusting brightness, contrast, and other parameters to standardize the input. The processed image is then analyzed using ML algorithms.
Image Recognition Technology accuracy depends mainly on the quality of the algorithm and the data training. Some systems have achieved accuracy comparable to or better than human levels in specific tasks. With powerful enough hardware and well-optimized software, image recognition can operate in real-time and vital areas (autonomous driving and video surveillance).
Features, patterns, colors, textures, shapes, or other defining aspects of the image are extracted. These features are then fed into a classifier, a trained machine learning model, to interpret the image. The classifier’s output is a prediction, determining what the image represents based on its learned knowledge. After obtaining the prediction from the classifier, next is post-processing.
This involves steps such as filtering or refining the results, which may also be performed to improve the usefulness of the output. In contrast, techniques such as data augmentation and transfer learning may be used to enhance performance further. With that in mind, it’s worth mentioning that several computing methods are used to foster image recognition technology in machine learning.
Notable Example Methods Include:
- Convolutional Neural Networks (CNNs). CNNs are a class of deep learning algorithms primarily used in image recognition. They process images directly and are adept at identifying spatial hierarchies or patterns within an image.
- Deep Learning. Deep learning uses artificial neural networks with several layers (deep structures) to model and understand complex patterns. It’s instrumental in processing large unstructured data sets, like images.
- Feature Extraction. This involves identifying an image’s key points or unique attributes, such as edges, corners, and blobs. Algorithms used for feature extraction include Scale-Invariant Feature Transform (SIFT), Speeded-Up Robust Features (SURF), and Histogram of Oriented Gradients (HOG).
- Custom Classification Output: Meanwhile, Vecteezy, an online marketplace of photos and illustrations, implements image recognition to help users more easily find the image they are searching for — even if that image isn’t tagged with a particular word or phrase. It really understands the nuance and stuff inside the image much better.
Remember, image recognition technology is yet another task within computer vision. At all costs, its algorithms are designed to analyze the content of an image and classify it into specific categories or labels, which can then be used. In many cases, many innovative tools today would be impossible without image recognition technology use and, by extension, computer vision.
As mentioned, image recognition technology has various applications, including facial recognition, object detection, medical imaging, quality control in manufacturing, augmented reality, and content moderation on social media platforms. Given the ever-evolving digital online and cloud computing space, image recognition technology is integral to many modern business systems.
Example Use Cases:
- Healthcare Industries: Image recognition technology analyzes medical imaging scans such as MRIs or CT scans to diagnose diseases and detect abnormalities. It can help identify patterns or anomalies within these images, enabling accurate diagnosis and timely intervention and treatment.
- Retail Marketplaces: To enhance the customer experience, image recognition is utilized in retail to enable customers to easily find products by taking photos. Additionally, it is employed in self-checkout systems to identify items and streamline the checkout process efficiently.
- Autonomous Vehicles: Image recognition is vital in helping autonomous vehicles understand their surroundings, including identifying obstacles, traffic signs, and pedestrians.
- Security Systems: Image recognition is used in security systems for surveillance and monitoring. It can detect and track objects, people, or suspicious activity in real-time, enhancing security measures in public spaces, corporate buildings, and airports to prevent incidents from happening.
One major problem with computer vision problems is that the input data can get big. Suppose an image is of the size 68 X 68 X 3. The input feature dimension then becomes 12,288. This will be even bigger if we have larger images (say, of size 720 X 720 X 3). If we pass such a considerable input to a neural network, the parameters will swell up to a HUGE number of numeric data.
Related Resource: Image Classification Using CNN | A Step-Wise Tutorial
But this depends on the number of hidden layers and units. This will result in more computational and memory requirements – not something most of us can handle. That’s where Convolutional Neural Networks (CNNs) come in. In Deep Learning, Convolutional Neural Networks (CNNs) or ConvNets are a class of deep neural networks most commonly applied to analyze visual imagery.
In the past few decades, Deep Learning has proved to be a potent tool because of its ability to handle large amounts of data. The interest in using hidden layers has surpassed traditional techniques, especially in pattern recognition. One of the most popular deep neural networks is Convolutional Neural Networks (CNN) or ConvNet in deep learning, especially in Computer Vision.
How Convolutional Neural Networks (CNNs) Help In Image Classification
With the help of CNN, or rather, an Artificial Neural Network (ANN), the Image Classification process involves extracting features from the image to observe some patterns in the dataset. An ANN system for image classification would be very costly since the trainable parameters become extremely large. For example, suppose we have a 50 X 50 image of a cat that we want to class.
Or rather, let’s say we want to train our traditional ANN on that image to classify it into a dog or a cat. The trainable parameters become – (50*50) * 100 image pixels multiplied by hidden layer + 100 bias + 2 * 100 output neurons + 2 bias = 2,50,302. We use filters when using CNNs. According to their purpose, filters of many different types help us exploit the spatial image locality.
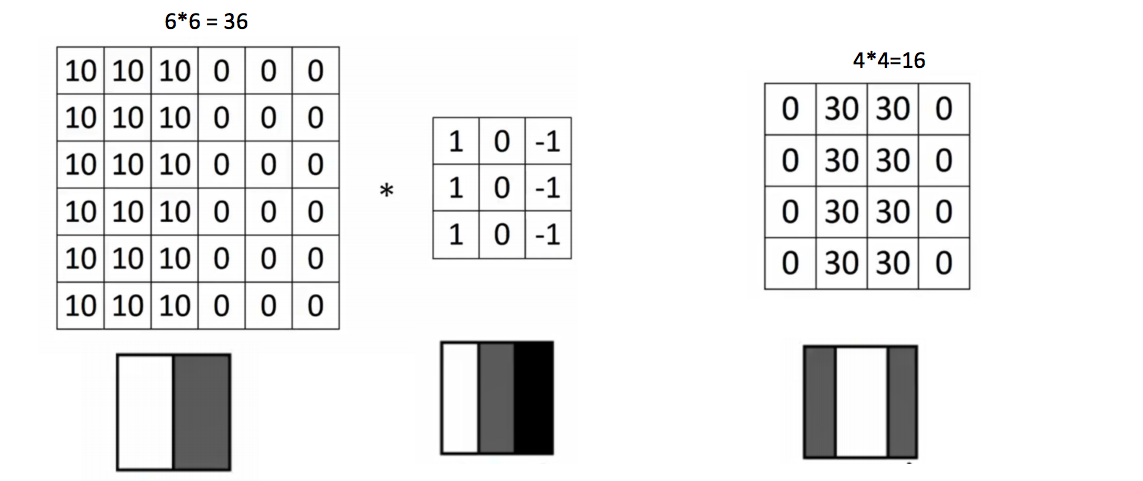
Convolution means a pointwise multiplication of two functions to produce a third function, including the image pixels matrix and the filter. We slide the filter over the image and get the dot product of the two matrices. The resulting matrix is called an “Activation Map” or “Feature Map”. Multiple convolutional layers extract features from the image and, finally, the output layer.
The effective use of CNN in image recognition has quickened architectural design exploration. In such a manner, a straightforward and successful CNN architecture called VGG was measured in layer design. To represent the depth capacity of the network, VGG had 19 deep layers compared to AlexNet and ZfNet. ZfNet small-size kernel aid improved the CNNs’ performance.
Utilizing Convolutional Neural Networks (CNNs) In Image Classification
To enumerate, a Convolutional Neural Network (CNN) is an artificial neural network used primarily for image recognition and processing. Partially, this is due to its ability to recognize patterns in images. Convolutional Neural Networks are useful for finding image patterns to identify objects, classes, and categories. They can also effectively classify audio, time series, and signal data.
CNNs can have tens or hundreds of layers that each learn to detect different features of an image. Filters are applied to each training image at various resolutions, and the output of each convolved image is used as the input to the next layer. The filters can start as straightforward features, such as brightness and edges, and increase complexity to features that uniquely define the object.
Usually, a convolutional neural network comprises an input, output, and many hidden layers. As a result, these layers perform operations that alter the data to learn features specific to the data. One essential benefit of utilizing CNNsis is that it provides an optimal architecture for uncovering an understanding (deep learning) of the critical features in image and time-series databases.
In other words, you can consider using CNNs when you have massive or complex big data (such as image data). When preprocessed, you can also use CNNs with signal or time-series data to work with the network structure. When working with CNNs, engineers, and scientists prefer to initially start with a pre-trained model that can be used to learn and identify features from a new data set.
Notable Use Cases:
- Medical Imaging: CNNs can examine thousands of pathology reports to visually detect the presence or absence of cancer cells in images.
- Audio Processing: Keyword detection can be used in any device with a microphone to detect when a particular word or phrase is spoken (“Hey Siri!”). CNNs can accurately learn and detect the keyword while ignoring all other phrases regardless of the environment.
- Object Detection: Automated driving relies on CNNs to accurately detect the presence of a sign or other object and make decisions based on the output.
- Synthetic Data Generation: Using Generative Adversarial Networks (GANs), new images can be produced for deep learning applications, including face recognition and automated driving.
Models like GoogLeNet, AlexNet, and Inception provide a starting point to explore deep learning, taking advantage of proven architectures built by experts. Three of the most common layers are convolution, activation or ReLU, and pooling.
Explanation:
- Convolution puts the input images through convolutional filters, each activating certain features from the pictures.
- Rectified linear unit (ReLU) allows for faster and more effective training by mapping negative values to zero and maintaining positive values. This is sometimes called activation because only the activated features are carried forward into the next layer.
- Pooling simplifies the output by performing nonlinear downsampling, reducing the parameters the network needs to learn.
These operations are repeated over tens or hundreds of layers, each learning to identify different features. Below is a sample illustration of a Convolutional Neural Network depicted by a car as input to feature deep learning methods, represented by connected cubes that get successively smaller and classified. Eventually, it’s an example of a network with many convolutional layers.

Filters are applied to each training image at different resolutions, and the output of each convolved image is used as the input to the next layer. With that in mind, let’s explore some common steps and the most significant stages that help utilize CNNs.
Stage #1: Shared Weights And Biases Classification
Unlike a traditional neural network, a CNN has shared weights and bias values, which are the same for all hidden neurons in a given layer. This means that all hidden neurons detect the same feature in different image regions, such as an edge or a blob. This makes the network tolerant to the translation of objects in an image. For example, consider a network trained to recognize cars. It can do so wherever the vehicle is in the image.
After undergoing deep learning to establish the core features in many layers, the architecture of a CNN shifts to classification. The next-to-last layer is a fully connected layer that outputs a vector of K dimensions (where K is the number of classes able to be predicted) and contains the probabilities for each class of an image being classified. The next layer of the CNN architecture uses a classification layer to provide the final classification output.
Stage #2: Digital Data Processing
It’s worth mentioning that image processing is often regarded as improperly exploiting the image to achieve a level of beauty or to support a widespread reality. However, image processing is most accurately described as a translation between a human viewing system and digital imaging devices. The human viewing system does not see the world in the same way as digital cameras.
One thing is sure: These digital cameras have additional sound effects and a massive bandwidth. Thus, there are significant differences between human and digital detectors and specific processing steps to achieve translation. As a rule of thumb, image editing should be approached scientifically so that others can reproduce and validate human results without interference.
This includes recording and reporting processing actions and applying the same treatment to adequate control images. However, the image data we collect or the photo information we produce is mainly immature, so it should not be used directly in applications for many reasons. Therefore, we must analyze it first, process it in advance (plus classification), and then apply it.
Stage #3: Dataset Model Gathering Process
After creating a massive data set of images/videos, we must analyze and annotate with meaningful features or characteristics. For instance, a dog image must be identified as a “dog.” If there are multiple dogs in an image, they may need data labeling with tags or bounding boxes, depending on the task at hand. Next, a neural network is fed and trained on these images.
As with the human brain, the machine must be taught to recognize a concept by showing it many examples. If the data has been labeled, supervised learning algorithms distinguish between different object categories (a cat versus a dog). If the data has not been tagged, the system uses unsupervised learning algorithms to analyze the various attributes of the images.
This helps determine the essential similarities or differences between the images. Notwithstanding, in deep learning, you don’t need hand-engineered features. You only require large amounts of data. The model is deep enough that the early layers extract valuable features first and then classify what the object is. The model itself learns the features.
Stage #4: Neural Networks Feeding And Training
Convolutional neural networks, or CNNs, are best for tasks concerned with image recognition because they can automatically detect significant features in images without human supervision. To accomplish this, CNNs have different layers. The first, a convolutional layer, applies filters (kernels) to a batch of input images to scan their pixels.
Then, it will mathematically compare the colors and shapes of the pixels, extracting important features or patterns from the images, like edges and corners. The CNN then uses what it learned from the first layer to look at slightly larger parts of the image, noting more complex features. It keeps doing this with each layer, looking at more significant parts of the picture until it decides what the image shows based on all the features it has found.
Stage #5: Inferences Conversion Into Actions
Once an image recognition system has been trained, new images and videos can be fed and compared to the original training dataset to make predictions. This allows it to assign a particular classification to an image or indicate whether a specific element is present. The system then converts those into inferences that can be implemented: A self-driving car detects a red light and stops; a security camera identifies a weapon being drawn and sends an alert.
Image Classification involves assigning labels or classes to input images. It is a supervised learning task where a model is trained on labeled image data to predict the class of unseen photos. CNN is commonly used for image classification as it can learn hierarchical features like edges, textures, and shapes, enabling accurate object recognition in images. Below are different layers.
1. Input Layer
Convolutional Neural Networks excel in this task because they can automatically extract meaningful spatial features from images. The input layer of a CNN takes in the raw image data as input. The images are typically represented as matrices of pixel values. The dimensions of the input layer correspond to the size of the input images (e.g., height, width, and color channels).
2. Convolutional Layers
Convolutional layers are responsible for feature extraction. They consist of filters (also known as kernels) that are convolved with the input images to capture relevant patterns and features. These layers learn to detect edges, textures, shapes, and other essential visual elements.
3. Pooling Layers
Pooling layers reduce the spatial dimensions of the feature maps produced by the convolutional layers. They perform downsampling operations (e.g., max pooling) to retain the most salient information while discarding unnecessary details. This helps achieve translation invariance and reduces computational complexity.
4. Fully Connected Layers
The output of the last pooling layer is flattened and connected to one or more fully combined layers. These layers function as traditional neural network layers and classify the extracted features. The combined layers learn complex relationships between features and output class probabilities or predictions.
5. Output Layer
The output layer represents the final layer of the CNN. It consists of neurons equal to the number of distinct classes in the classification task. The output layer provides each class’s classification probabilities or predictions, indicating the likelihood of the input image belonging to a particular class.
How ResNet Can Help In Deploying An Image Recognition Application
Localization entails pinpointing the exact location of an object within an image, typically restricted by drawing bounding boxes around each object. This analysis enriches our understanding of images and propels further exploration or actions based on the identified objects. Various resources are available for image annotation, preprocessing, augmentation, and algorithm selection.
In particular, they all can be customized to fit your specific needs. Among the many image recognition models, ResNet 50 stands out as the most popular and is my model of choice. ResNet is a type of convolutional neural network that brought the ideas of residual learning and skipped connections to the forefront. This allows for the training of deeper models with greater ease.

While both involve interpreting images, Image Recognition Technology and Object Detection Systems have distinct roles. In most cases, image recognition helps identify what an entire image represents, like recognizing a photo as a landscape, a portrait, or a night scene. On the contrary, object detection goes further by locating and identifying multiple objects within an image.
For example, while image recognition could identify a picture as a street scene, object detection could identify and locate cars, pedestrians, buildings, and even specific breeds of dogs in the same picture. By all means, object detection systems amalgamate image recognition technology and localization, yielding accurate identification and placement of objects within an image.
A. Data Collection
Most accurate image classification models are pre-trained models already trained on a large dataset of images. This means you don’t need many photos to get precise results. Even 100 images per classification can produce above 80% accuracy. You can find open-source image datasets on Kaggle for your project.
B. Data Annotations
ResNet (Residual Network) is a convolutional neural network that democratized residual learning and skip connections concepts. This enables developers to train much deeper models. Once you have an unlabeled dataset of images, it is essential to label it and validate the labels before analyzing the image dataset.
C. Data Preprocessing
Before model training, you must preprocess the images by loading them, cleaning the data, and converting them into numerical matrices. Then, you can use various augmentation techniques to increase the image size. These techniques include cropping, flipping, color shifting, scaling, distortion, translation, and more.
D. Model Selection
Residual Networks, or ResNets, learn residual functions —while referencing to the layer inputs—instead of learning unreferenced functions. Instead of hoping each few stacked layers directly fit a desired underlying mapping, residual nets let these layers best fit in a residual mapping. This stage involves experimenting with different CNN models and evaluating their performance by training them on the smaller training dataset. Ultimately, you will determine the best-performing model.
E. Model Evaluation
In this scenario, you’ve chosen ResNet 50 and plan to optimize its hyperparameters for improved accuracy. Evaluating the model on the test dataset is crucial to gather essential information on its accuracy and stability. Afterward, you can select the best-performing model and save its weight.
F. API Deployment
Finally, you create an API or web application to load the saved model weights and predict the image class. This part requires more testing, as you want to assess the throughput and performance of the model over time and on unseen data. Once satisfied with your results, you can deploy the web application with the model to production. This process may initially sound confusing, but as you begin working on an image classification project, you will discover multiple solutions for performing the same tasks. The test-and-learn process will help you build a more robust data science portfolio to showcase to your potential clients.
The Most Notable Limitations That Image Recognition Technology Face
There are still some challenges that image recognition technology (design, use, and deployment) often faces. For instance, privacy concerns are related to image recognition technology, particularly facial recognition. The collection and use of personal data without consent, the potential misuse of the technology, and the risk of false identifications are some of the main concerns.
Here is another drawback: To apply Augmented Reality (AR), a machine must first understand all of the objects in a scene, both in terms of what they are and where they relate to each other. If the machine cannot adequately perceive its environment, there’s no way it can apply AR on top of it. The same goes for self-driving cars, autonomous mobile robots, and other related systems.
For Instance:
- Data Dependence: If using supervised learning to label images, the accuracy of image recognition relies heavily on the quality and quantity of the training data, including the quality of its labeling process. Usually, collecting diverse and representative training data, ensuring accurate labeling through human verification, and utilizing transfer learning with pre-trained models can help mitigate this.
- Adversarial Attacks: Slight, often imperceptible alterations to an image can mislead image recognition systems. For example, a malicious attack could involve adding small perturbations to a stop sign image, which would cause an image recognition system to misclassify it as a speed limit sign. To overcome this, robust machine learning models should be developed by incorporating adversarial training, defensive distillation, or certified defenses that provide guarantees against such attacks.
- Delivery Complexity: While human vision can understand the context and relationships between objects, image recognition systems often struggle with this. Advanced machine learning algorithms trained on massive datasets are generally more adept at providing accurate interpretations of images.
As you can see, despite its wide-ranging applications, image recognition isn’t without limitations. Remember, image recognition technology is a definitive classification problem, and CNNs have a history of high accuracy for this problem. The role of a CNN is to filter lines, curves, and edges and, in each layer, transform this filtering into a more complex image, making recognition easier.
In Conclusion;
Image Recognition Technology is an integral part of the tools we often use — from the facial recognition feature that unlocks smartphones to mobile check bank deposit apps. Still, image recognition technology is also used in areas like medical imaging to identify tumors, broken bones, and other aberrations and in factories to detect defective products on the assembly line.
With the help of image recognition technology systems, a machine can identify objects in a scene just as quickly as a human can — and often faster and at a more granular level. Once a model recognizes particular elements, it can be programmed to respond to a specific action. As a result, this makes its applicability an integral part of many technology-based business sectors.
Other More Related Resource References:
- What You Can Learn In AWS Image Processing As A Beginner
- Face ID Checks | How It Helps Power Cloud Computing Security
- AI-Integrated Face Recognition | Ultimate Solution To Security Threats
- Business OCR Solutions | IDV Systems Upgrade Via Automated Data
- How To Extract Texts From PDF Document Files In Simple Steps
In other words, Image Recognition is a digital image or video process that identifies and detects an object or feature. AI is increasingly becoming highly effective in using this technology. AI can search for images on social media platforms and equate them to several datasets to determine which ones are important in image search. Please let us know your additional input in our comments.