All of us know that when it comes to creative writing, avoiding duplicate content starts by creating unique quality content for your website. However, the practices to avoid the risk of others copying you can be more complex. The safest way to avoid duplicate content issues is to think carefully about site structure and focus your users and their journeys onsite.
When content duplication occurs due to technical factors, the tactics covered should alleviate the risk to your website. Also, when considering duplicate content risks, it is important to send the right signals to Google to mark your content as the source. This is true, especially if your content is syndicated or you have found other sources that have replicated your content.
Depending on how the duplication has occurred, you may employ one or many tactics to establish content as having a source and recognize other versions as duplicates. That aside, many people are more afraid of duplicate content than spammy comments or links. There are so many myths around duplicate content that people think it causes a penalty in SERPs.
And that their website pages will compete against each other and hurt their website. We often see forum posts, Reddit threads, technical audits, tools, and even SEO news websites publishing articles that show people clearly don’t understand how Google treats duplicate content. That’s why we created this guide to help you prevent duplicate content on your website.
Understanding What Duplicate Content Entails In Creative Writing
To enumerate, Duplicate Content is similar or exact copies of content on other websites or different pages on the same website. Large amounts of duplicate content on a website can negatively impact Google rankings. In other words, duplicate content is word-for-word, like the content appearing on another page. But it also applies to content similar to other content…
In terms of similar content, we mean even if it’s slightly rewritten. Google tried to kill off the myths around duplicate content years ago. Susan Moska posted on the Google Webmaster Blog in 2008: Let’s put this to bed once and for all, folks: There’s no such thing as a “duplicate content penalty.” At least, not in the way most people mean when they say that.
You can help your fellow webmasters by not perpetuating the myth of duplicate content penalties! Sorry, we failed you, Susan. According to Semrush, Duplicate Content is defined as an exact copy of content found elsewhere. However, duplicate content can also refer to almost identical content (such as just swapping a product, brand name, or location name only).
Googlers have published many great posts. But, without a canonical URL, Google will identify which version of the URL is objectively the best version to show to users in Search. We will summarize the best parts, but we recommend reading over the posts to gather more insights that can help avoid duplicate content from happening on your website.
The General Google Thoughts On Duplicate Content:
- Duplicate content doesn’t cause your site to be penalized
- Google designed algorithms to prevent duplicate content from affecting webmasters
- Duplicate content is not grounds for action unless it intends to manipulate search results
- Google tries to determine the source of the content and displays that one
- They can’t consolidate the signals if they can’t crawl all the versions
Simply swapping a few words out will not necessarily save a page from being deemed as duplicated content. As a response, your organic search performance can see a negative effect. This type of content also refers to content that is the same across multiple web pages on your site or across two or more separate sites. However, there are methods to prevent duplicates.
The Main Overuse Causes And Impacts On Creative Writing Strategy
Googlers know that users want diversity in the search results and not the same article repeatedly, so they consolidate and show only one version. The new Google algorithm changes, and crawling bots group the various versions into a cluster, display the “best” URL, and consolidate various signals (such as links) from pages within that cluster to the one shown.
The worst thing that can happen from this filtering is that a less desirable page version will be shown in search results. They even said, “If you don’t want to worry about sorting through duplication on your website, you can let us worry about it instead.” Do not block access to duplicate content. What if someone is duplicating your content without permission?
Well, you can request to have it removed by filing a request under the Digital Millennium Copyright Act. To specify a Canonical URL for duplicate or similar pages to Google Search, you can indicate your preference using several methods. These are, in order of how strongly they can influence canonicalization, and they usually differ from website to website.
Consider the following:
- Redirects: A strong signal that the redirect’s target should become canonical.
rel="canonical"linkannotations: A strong signal that the specified URL should become canonical.- Sitemap inclusion: A weak signal that helps the URLs included in a sitemap become canonical.
Remember that these methods can stack and thus become more effective when combined. This means that when you use two or more of the methods, that will increase the chance of your preferred canonical URL appearing in search results. While we encourage you to use these methods, none are required; your website will likely do fine without specifying them.
Google generally doesn’t want to rank website pages with duplicate content. Google states that: “Google tries hard to index and show pages with distinct information.” So if you have pages on your site WITHOUT distinct information, it can hurt your search engine rankings. Specifically, here are the three main issues that websites with lots of duplicate content run into.
The main causes:
- HTTP and HTTPS
- www and non-www versions
- Parameters and faceted navigation
- Session IDs and trailing slashes
- Alternate page versions such as m. or AMP pages or print
- Development and hosting environments
- Index pages plus pagination and scrapers
- Preferred Country and Language versions
If you use a CMS, such as WordPress, Wix, or Blogger, you might be unable to edit your HTML directly. Instead, your CMS might have a search engine settings page or another mechanism to tell search engines about the canonical URL. Search for instructions about modifying the <head> of your page on your CMS (for example, search for “WordPress set the canonical”).
Why It Is Important To Check On Your Overall Website Content
The aftermath of duplicate content is significant to many webmasters and web-based businesses. As we will highlight a few methods to help you solve your duplicate content problems on your website, the solution will depend on the situation. For example, you can’t just do nothing and hope Google gets it right. We wouldn’t recommend this course of action at all.
Otherwise, you may have read previously that Google will cluster the pages and consolidate the signals, effectively handling duplicate content issues for you. While it’s generally not critical to specify a canonical preference for your URLs, there are several reasons why you would want to explicitly tell Google about a canonical page in a set of duplicate or similar pages.
Below are a few things why it matters:
- Specify which URLs you want people to see in search results. You might prefer people to reach your green dresses product page through the likes of;
rather than. - Consolidate signals for similar or duplicate pages. It helps search engines to be able to consolidate the signals they have for the individual URLs (such as links to them) into a single, preferred URL. This means that signals from other sites to
get consolidated with links toif the latter becomes canonical. - Simplify tracking metrics for a piece of content. Getting consolidated metrics for specific content can be more challenging with various URLs.
- Avoid spending crawling time on duplicate pages. You may want Googlebot to get the most out of your site, so it should spend time crawling new (or updated) website pages rather than crawling duplicate versions of the same content.
With that in mind, there are a few known factors for you to consider below:
Less Organic Traffic: This is pretty straightforward. Google doesn’t want to rank pages that use content that’s copied from other pages in Google’s index. (Including pages on your very own website) For example, your website has three pages with similar content. Google isn’t sure which page is the “original.” So all three pages will struggle to rank.

Penalty (Extremely Rare): Google has said that duplicate content can lead to a penalty or complete deindexing of a website. However, this is super rare. And it’s only done when a site purposely scraps or copies content from other websites. So if you have many duplicate pages on your website, you probably don’t need to worry about a “duplicate content penalty.”
Fewer Indexed Pages: This is especially important for websites with many pages (like eCommerce websites). Sometimes Google doesn’t just downrank duplicate content. It refuses to index it. So if you have pages on your website that aren’t getting indexed, it could be because your crawl budget is wasted on duplicate content.
In other words, website pages created with the same content can result in several ramifications in Google Search results and, occasionally, lead to various search engine penalties.
The most common duplicate content issues include:
- The wrong version of pages showing in SERPs
- Key pages unexpectedly not performing well in SERPs or experiencing indexing problems
- Fluctuations or decreases in core site metrics (traffic, rank positions, or E-A-T Criteria)
- Other unexpected actions by search engines as a result of confusing prioritization signals
Although no one is sure which content elements will be prioritized and deprioritized by Google, the search engine giant has always advised webmasters and content creators to ‘make pages primarily for users, not for search engines.’ With this in mind, the starting point for any webmaster or SEO should be to create unique content that brings unique value to users.
However, this is not always easy or even possible. Factors such as templating content, search functionality, UTM tags, sharing of information, or syndicating content can be fraught with the risk of duplication. Ensuring that your website does not run the risk of duplication of content entails a combination of a clear architecture, regular maintenance, and technical skills.
As well as an understanding to combat the creation of identical content as much as possible. Fortunately, there are many methods to prevent duplication or minimize the impact of duplicate content that technical fixes can handle.
The Topmost Methods To Prevent Duplicate Content On Your Website
To enumerate, according to Google: Duplicate Content refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin. People mistake duplicate content for a penalty because of how Google handles it. The duplicates are just being filtered in the search results.
You can see this for yourself by adding &filter=0 to the end of the URL and removing the filtering. Adding &filter=0 to the end of the page URL on a search for “raleigh seo meetup” will show me the same page twice. We are not saying Meetup has done a good job with this since they indicate the two versions (HTTP & HTTPS) are correct.
Particularly in their use of canonical tags, we think it shows that the same page (or similar pages) are indexed, and only the most relevant is being shown. It’s not that the page is necessarily competing or doing any harm to the website itself. Matt Cutts states that 25% to 30& of the web is duplicate content, and most webmasters and users won’t realize that.
A recent study by Raven Tools based on data from their site auditor tool found a similar result, in that 29% of pages had duplicate content regarding user access. That being said, there are a few methods that you can deploy on your website.
1. Take Note Of Your Overall Website URLs
The very first thing here is to watch for the same content on different website URLs. This is the most common reason that duplicate content issues pop up. For example, let’s say that you run an eCommerce website. And you have a product page that sells t-shirts. If everything is set up right, every size and color of that t-shirt will still be on the same website URL.
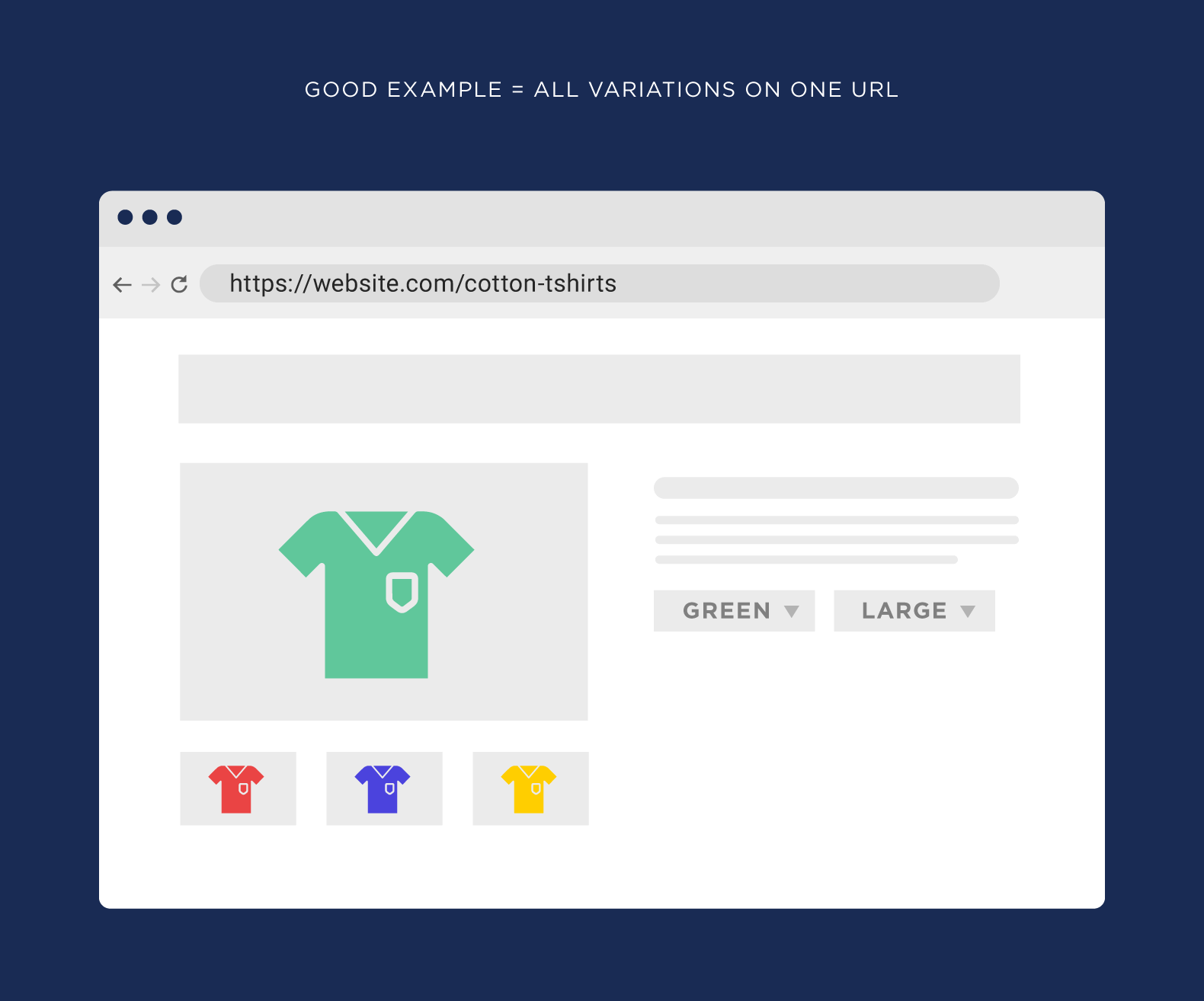
But sometimes you’ll find that your website creates a new URL for every different version of your product… which results in thousands of duplicate content pages. In another example: If your website has a search function, those search result pages can get indexed too. Again, this can easily add 1,000+ pages to your website. All of which contain duplicate content.
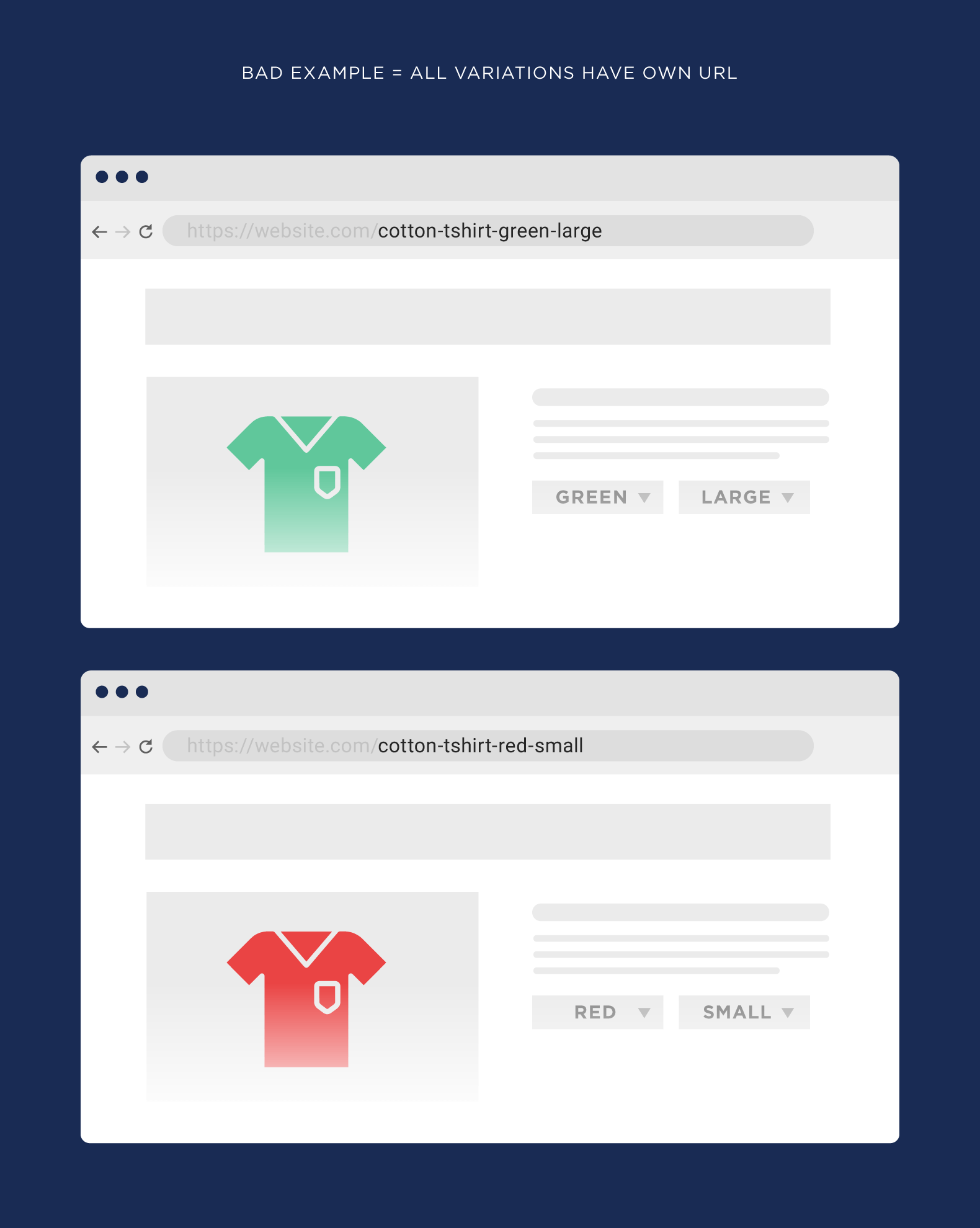
What should you do if your content has been copied and you have not used a canonical tag to signify content originality?
- Use Search Console to identify how regularly your site is being indexed.
- Contact the webmaster responsible for the site that has copied your content and ask for accreditation or removal.
- Use self-referencing canonical tags on all new content created to ensure that your content is recognized as the ‘true source’ of the information.
There are many different methods and strategies to prevent the creation of duplicate content on your website and to prevent other websites from benefiting from copying your content, as we are going to list below.
1.1. Taxonomies
The first step is to pick a canonical URL for each of your website pages and submit them in a sitemap form for easier crawling by bots. All pages listed in a sitemap are suggested as canonicals; Google will decide which pages (if any) are duplicates based on the content similarity. Supplying the preferred canonical URLs in the sitemaps is a simple way of defining canonicals.
Especially for a large website, sitemaps are a useful way to tell Google which pages you consider most important on your site. As a starting point, it is wise to have a general look at your site’s taxonomy. Whether you have a new, existing, or revised document, mapping out the pages from a crawl and assigning a unique H1 and focus keyword is a great start.
Organizing your content in a topic cluster can help you develop a thoughtful strategy that limits duplication. Google supports rel canonical link annotations as described in RFC 6596. You can provide the rel="canonical" link annotations in two ways.
Consider the following:
We recommend that you choose one of these and go with that; while supported, using both methods at the same time is more error-prone (for example, you might provide one URL in the HTTP header, and another URL in the rel="canonical" link element).
Just as we aforementioned, a rel="canonical" link element (also known as a canonical element) is an element used in the head section of HTML to indicate that another page represents the content on the page. Suppose you want to be the canonical URL, even though various URLs can access it.
Indicate this URL as canonical with these steps:
- Add a
<link>element with the attributerel="canonical"to the<head>section of duplicate pages, pointing to the canonical page. For example:<html> <head> <title>Explore the world of dresses</title> <link rel="canonical" href="https://example.com/dresses/green-dresses" /> <!-- other elements --> </head> <!-- rest of the HTML -->
- If the canonical page has a mobile variant on a separate URL, add a
rel="alternate"linkelement to it, pointing to the mobile version of the page:<html> <head> <title>Explore the world of dresses</title> <link rel="alternate" media="only screen and (max-width: 640px)" href="https://m.example.com/dresses/green-dresses"> <link rel="canonical" href="https://example.com/dresses/green-dresses" /> <!-- other elements --> </head> <!-- rest of the HTML -->
- Add any
hreflangor other elements that are appropriate for the page.
Use absolute paths rather than relative paths with the rel="canonical" link element. Even though Google supports relative paths, they can cause problems in the long run (for example, if you unintentionally allow your testing site to be crawled), and thus we don’t recommend them.
Examples:
Good:
Bad: /dresses/green/greendress.html
The rel="canonical" link element is only accepted if it appears in the <head> section of the HTML, so make sure at least the <head> part of the section is valid HTML. If you use JavaScript to add the rel="canonical" link element, make sure to inject the canonical link element properly.
1.2. Canonicals
The most important element in combating duplication of content on your website or across multiple websites is Canonical Tags. The rel=canonical element is a snippet of HTML code that makes it clear to Google that the publisher owns a piece of content even when it can be found elsewhere. These tags denote to Google which version of a page is the ‘main version.
The canonical tag can be used for print vs. web versions of content, mobile and desktop page versions, or multiple locations targeting pages. It can also be used for other instances where duplicate pages stem from the main version page. There are two types of canonical tags, those that point to a page and those that point away from a page.
Those that point to another page tell search engines that another version of the page is the ‘master version. The other is those that recognize themselves as the master version, also known as self-referencing canonical tags. Referencing canonicals is essential to recognizing and eliminating duplicate content, and self-referencing canonicals are a matter of good practice.
1.3. Metas
Another useful technical item to look for when analyzing the risk of identical content on your site is Meta robots and the signals you send to search engines from your pages. Meta robots tags are useful if you want to exclude a certain page, or pages, from being indexed by Google and would prefer them not to show in search results.
Adding the ‘no index’ meta robots tag to the page’s HTML code effectively tells Google you don’t want it to be shown on SERPs. This is the preferred method for Robots.txt blocking, as this methodology allows for more granular blocking of a particular page or file, whereas Robots.txt is often a larger-scale undertaking.
Although this instruction can be given for many reasons, Google will understand this directive and should exclude duplicate pages from SERPs.
1.4. Parameters
URL Parameters indicate how to crawl sites effectively and efficiently to search engines. Parameters often cause content duplication as their usage creates copies of a page. For example, if there were several different product pages of the same product, it would be deemed as matching content by Google.
However, parameter handling facilitates more effective and efficient crawling of sites. The benefit of search engines is proven, and their resolution to avoid creating duplicate content is simple. Particularly for larger sites and sites with integrated search functionality, it is important to employ parameter handling through Google Search Console and Bing Webmaster Tools.
By indicating parameterized pages in the respective tool and signaling to Google, it can be clear to the search engine that these pages should not be crawled and what, if any, additional action to take.
1.5. Duplicates
Several structural URL elements can cause duplication issues on a website. Many of these are caused because of the way search engines perceive URLs. If there are no other directives or instructions, a different URL will always mean a different page.
If not addressed, this lack of clarity or unintentional wrong signaling can cause fluctuations or decreases in core site metrics (traffic, rank positions, or E-A-T Criteria). As we have already covered, URL Parameters caused by search functionality, tracking codes, and other third-party elements can cause multiple versions of a page to be created.
The most common ways that duplicate versions of URLs can occur include HTTP and HTTPS versions of pages, www. and non-www., and pages with trailing slashes and those without.
In the case of www. vs. non-www and trailing slash vs. non-trailing slashes, you need to identify the most commonly used on your site and stick to this version on all pages to avoid the risk of duplication. Furthermore, redirects should be set up to direct to the version of the page that should be indexed and remove the risk of duplication, e.g., mysite.com > www.mysite.com.
On the other hand, HTTP URLs represent a security issue as the HTTPS version of the page would use encryption (SSL), making the page secure.
1.6. Redirects
Redirects are very useful for eliminating duplicate content. Pages duplicated from another can be redirected and fed back to the main version of the page. Where there are pages on your site with high traffic volumes or link value duplicated from another page, redirects may be a viable option to address the problem.
When using redirects to remove duplicate content, remember two important things: always redirect to the higher-performing page to limit the impact on your site’s performance and, if possible, use 301 redirects. If you want more information on which redirects to implement, you can always check out this guide to 301 redirects to gather more useful information.
If you can change the configuration of your server, you can use a rel="canonical" HTTP header rather than an HTML element to indicate the canonical URL for a document supported by Search, including non-HTML documents such as PDF files. As illustrated below, Google currently supports a very specific method for web search results only.
If you publish content in many file formats, such as PDF or Microsoft Word, each on its URL, you can return a rel="canonical" HTTP header to tell Googlebot the canonical URL for the non-HTML files. For example, to indicate that the PDF version of the .docx version should be canonical, you might add this HTTP header for the .docx version of the content.
Consider the following:
HTTP/1.1 200 OK Content-Length: 19 ... Link: <https://www.example.com/downloads/white-paper.pdf>; rel="canonical" ...
As with the rel="canonical" link element, use absolute URLs in the rel="canonical" HTTP header, and as per RFC2616, use only double quotes around the URL.
2. Check Your Indexed Website Pages And Correct Redirects
One of the easiest ways to find duplicate content is to look at the number of pages from your website indexed in Google. You can do this by searching for site:example.com in Google. Or, rather, check out your indexed website pages in the Google Search Console, to be precise. Either way, this number should align with the number of pages you manually created.
If the number were 16,000 or 160,000, we’d know that many pages were automatically added. And those pages would likely contain significant amounts of duplicate content. Sometimes you don’t just have multiple versions of the same page… but of the same website. Although rare, I’ve seen it happen in the wild many times.
This issue arises when your website’s “WWW” version doesn’t redirect to the “non-WWW” version. (Or vice versa) This can also happen if you switched your website to HTTPS… and didn’t redirect the HTTP website. In short, all the different versions of your website should end up in the same place.
3. Keep An Eye Out For 301 Redirects And Similar Content
In most cases, 301 redirects are the easiest way to fix duplicate content issues on your website (besides deleting pages altogether). So if you find a bunch of duplicate content pages on your website, redirect them back to the original. Once Googlebot stops by, it will process the redirect and ONLY index the original content (it can help the original page to rank).

Duplicate content doesn’t ONLY mean content copied word-for-word from somewhere else. Google defines duplicate content as: ”Duplicate content generally refers to substantive blocks within or across domains that match other content or are appreciably similar. Mostly, this is not deceptive in origin. Examples of non-malicious duplicate content could include:
Discussion forums that can generate both regular and stripped-down pages targeted at mobile devices.” So, even if your website content is technically different from what’s out there, you can still run into duplicate content problems. This isn’t an issue for most sites. Most sites have a few dozen pages. And they write unique stuff for every page.
But there are cases where “similar” duplicate content can crop up. For example, let’s say you run a website that teaches people how to speak French. And you serve the greater Boston area. You might have one services page optimized around the keyword: “Learn French Boston.”

And another page that’s trying to rank for “Learn French Cambridge.” Sometimes the content will technically be different. For example, one page has a location listed for the Boston location. And the other page has the Cambridge address.
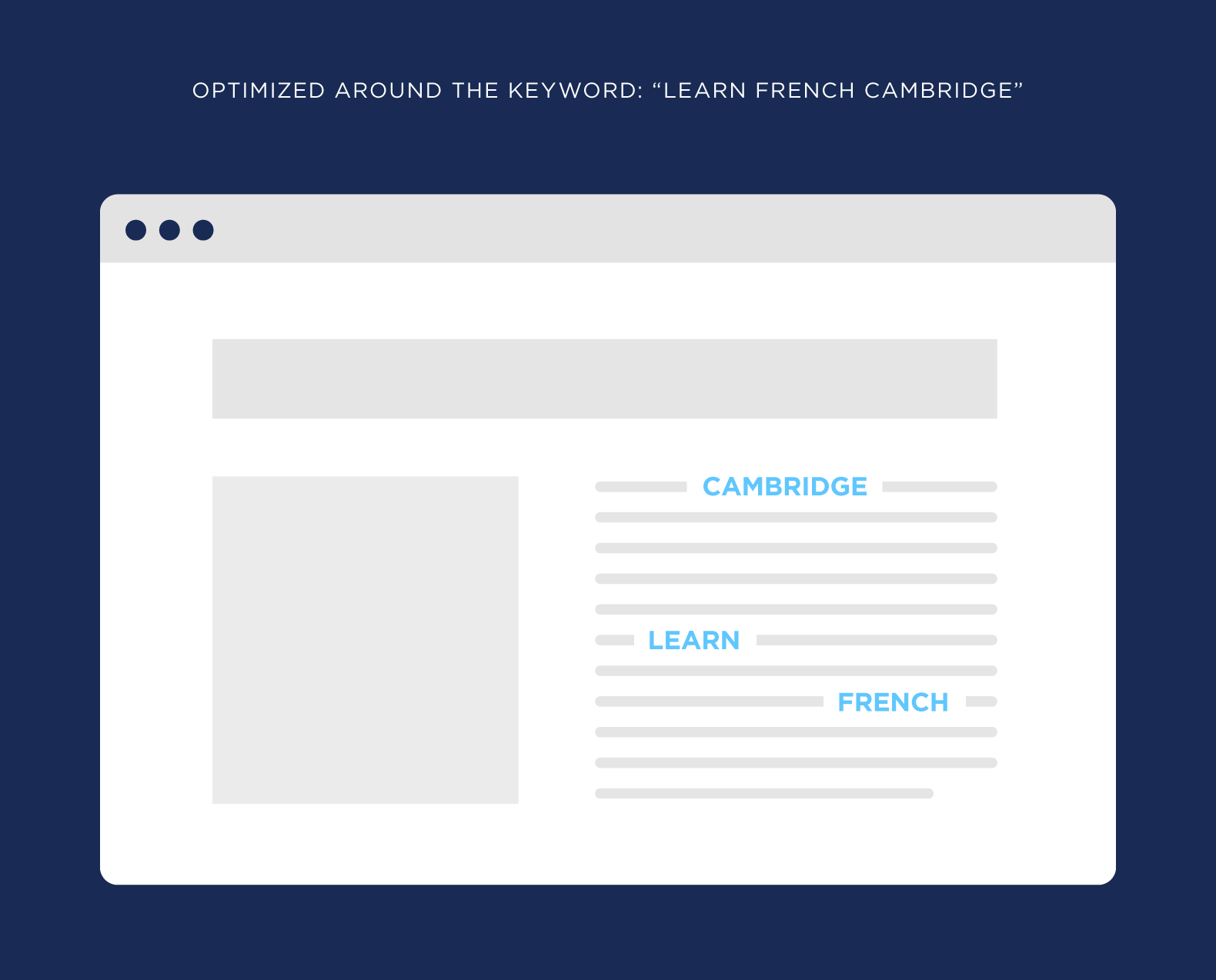
But for the most part, the content is super similar. That’s technically duplicate content.
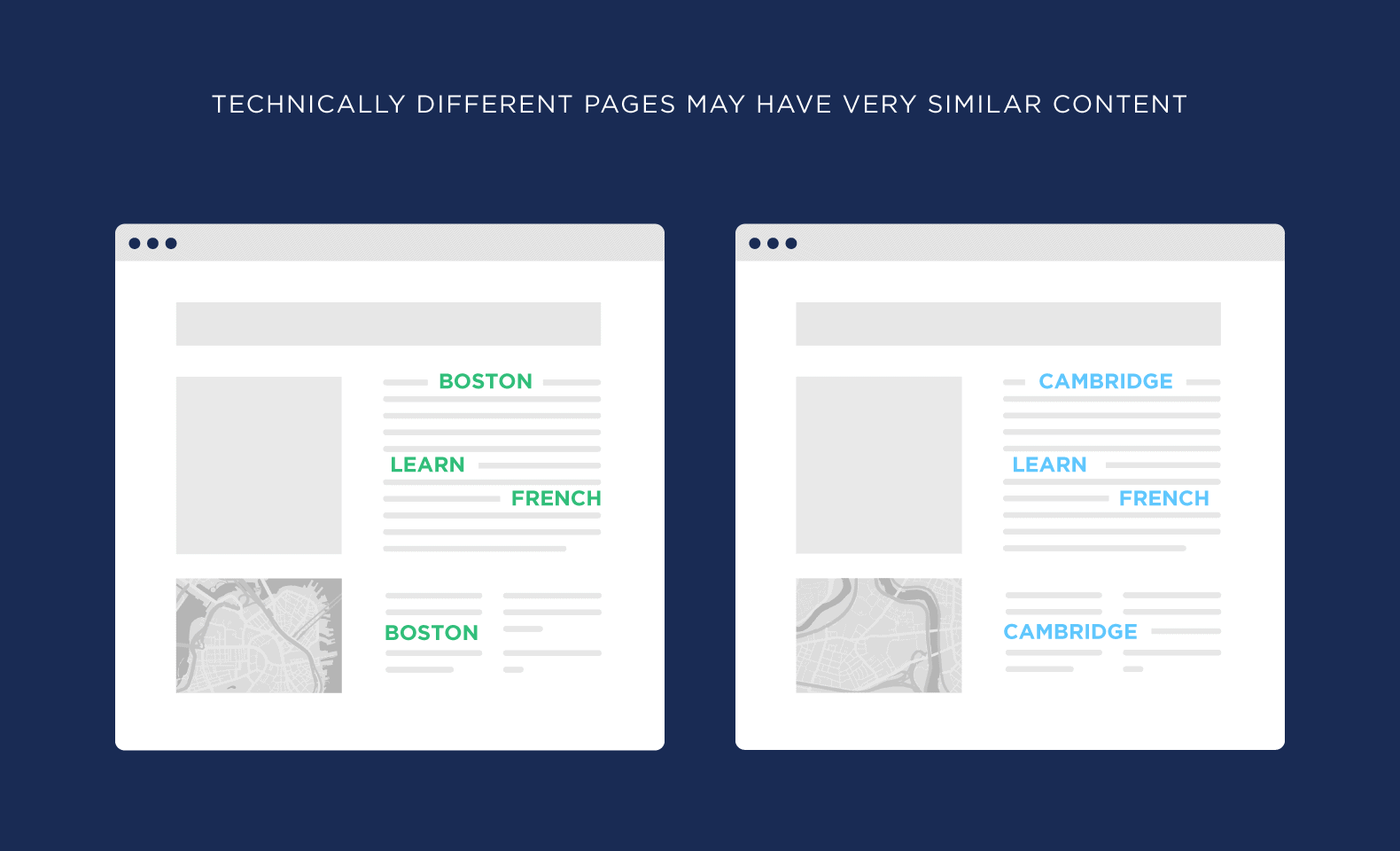
Is it a pain to write 100% unique content for every page on your website? Yup. But it’s a must if you’re serious about ranking every page on your website.
4. Consolidate Pages Using A Duplicate Content Tool
As we mentioned, if you have many pages with duplicate content, you probably want to redirect them to one page (or use the canonical tag). But what if you have pages with similar content?

Well, you can grind out unique content for every page… OR consolidate them into one mega page. For example, let’s say you have 3 blog posts on your site that are technically different… but the content is pretty much the same. You can combine those 3 posts into one amazing blog post that’s 100% unique. Something like ”SEO In 2023: The Definitive Guide.”
Because you removed some duplicate content from your site, that page should rank better than the other 3 pages combined. Luckily, a few SEO Tools have features designed to spot duplicate content. Examples of freemium tools to check for duplicate content include Grammarly – which offers a plagiarism checker, grammar checker, word choice, and sentence structure.
You can also consider using Plagium – a free quick search or a premium deep search — as well as Plagiarismcheck.org – which detects exact matches and paraphrased text. They can detect similarities in any text and produce unbiased similarity reports.
5. Use The Canonical Tag In Your Content Writing Strategy
At all costs, Canonical Tags consolidate signals and pick your preferred version. It’s a pet peeve of mine when a website has canonical tags set correctly, and we see an audit that says there are duplicate content issues. It’s not an issue, so don’t say it is.
The rel=canonical tag tells search engines: “Yes, we have a bunch of pages with duplicate content. But this specific page is the original. You can ignore the rest”. Google said a canonical tag is better than blocking pages with duplicate content.

(For example, blocking Googlebot using Custom Robots.txt File or with a noindex tag in your web page HTML) So if you find a bunch of pages on your website with duplicate content, you want to either:
- Delete them
- Redirect them
- Use the canonical tag
By the same token, if you use WordPress, you might have noticed that it automatically generates tag and category pages for you by default, right? These pages are huge sources of duplicate content. So they’re useful to users, we recommend adding the “noindex” tag to these pages. That way, they can exist without search engines indexing them.
You can also set things in WordPress up so these pages don’t get generated at all. You should use the redirects method to get rid of existing duplicate pages. While keeping in mind that all redirection methods —301 and 302 redirects, meta-refresh, JavaScript redirects — have the same effect on Google Search.
However, the time it takes for search engines to notice the different redirect methods may differ. For the quickest effect, use 3xx HTTP (also known as server-side) redirects. Suppose your page can be reached in multiple ways.
Consider the following:
https://home.example.comhttps://www.example.com
Pick one of those URLs as your canonical URL, and use redirects to send traffic from the other URLs to your preferred URL.
Summary Notes:
For beginners or professional creative content writers, myths about duplicate content penalties must die. Audits, application tools, and misunderstandings need correct information, or this myth might be around for another 10 years. There are plenty of ways to consolidate signals across multiple pages; even if you don’t use them, Google will try to consolidate them.
To help with sites’ localization efforts, for canonicalization purposes, Google prefers URLs that are part of hreflang clusters. For example, if and reciprocally point to each other with hreflang annotations, but not to
Otherwise, the pages for de-de and de-ch will be preferred as canonicals instead of the /de-at/ a page that doesn’t appear in the hreflang cluster. Be that as it may, read more about troubleshooting and fixing canonicalization issues in detail.
Other problems are scraping/spam, but for the most part, this would be caused by the websites themselves. Don’t disallow in robots.txt, don’t nofollow, don’t noindex, don’t canonical from pages targeting longer-tail to overview-type pages, but do use the signals mentioned above for your particular issues to indicate how you want the content to be treated.